
A Maturidade Final Entre Reescrever e Resignação
Introdução: O Dilema Real
Todo senior em tecnologia chega a um ponto na carreira em que enfrenta um sistema legado que funciona, mas incomoda. É o sistema que paga as contas, que processa transações críticas, que segura clientes importantes—e que, simultaneamente, paralisa a velocidade de inovação. Ele não está quebrado. Exatamente aí mora o problema: não está quebrado o suficiente para justificar um rewrite de 2-3 anos, mas está estável o suficiente para que a organização continue negligenciando-o.
A decisão que enfrenta não é técnica, é estratégica. E ela define a maturidade final de um CTO, arquiteto ou engenheiro sênior: saber quando reescrever é erro catastrófico, e como evoluir sem parar o negócio.
Este artigo coloca duas mentiras lado a lado e as queima. A primeira: “Devemos reescrever tudo do zero.” A segunda: “Devemos apenas refatorar incrementalmente para sempre.” A realidade que separa amadores de especialistas está nos degraus entre essas extremidades.
Parte 1: Quando Reescrever é um Erro Catastrófico
O Fantasma da Taxa de Falha
Não existe consenso acadêmico sobre qual é exatamente a taxa de fracasso de rewrites completos. Mas existem evidências suficientes. McKinsey relata que 70% dos programas de transformação em larga escala não alcançam seus objetivos. A Thoughtworks e a comunidade de engenheiros documentam um padrão recorrente: rewrites sobreestimam o que conseguem fazer e subestimam o que perdem.
Por que isso acontece? Porque um rewrite completo confunde “começar do zero” com “resolver o problema”. Na verdade, o que está acontecendo é muito mais sinistro:
Você não está reconstruindo o sistema. Você está reconstruindo o conhecimento.
Um sistema legado de 10-20 anos não é apenas código. É um repositório de decisões de negócio: casos extremos tratados em patches, integrações quirky que ninguém lembra por quê, dados limpos lentamente em triggers noturnos. Tudo isso é conhecimento tácito. Quando você reescreve, você tira esse conhecimento da base de código e o coloca na cabeça de engenheiros novos—ou, piores, em whiteboards onde ele é esquecido.
Um engenheiro experiente que trabalhou em sistemas legados grandes conhece a história verdadeira. O rewrite não falha porque os engenheiros são incompetentes. Falha porque:
- Surpresas escondidas aparecem no meio do rewrite. O sistema processava casos extremos que ninguém documentou. Quando você remove aquela lógica de 5 linhas em um stored procedure, 20.000 registros por mês começam a processar incorretamente—e ninguém descobre até meses depois em produção.
- O cronograma é 3x mais longo que estimado. Não porque a equipe é lenta, mas porque estimativas para sistemas que você não entende bem são fantasias. Você descobre dependências escondidas, acoplamentos inesperados, dados sujos que precisam limpeza.
- A equipe legada continua cuidando do sistema antigo enquanto também tenta construir o novo. Você divide cognição entre dois sistemas, e nenhum dos dois recebe atenção total. Bugs críticos no sistema antigo explodem e roubam semanas da equipe nova.
- O negócio muda enquanto você reescreve. Requisitos que eram verdade quando o rewrite começou são obsoletos no ano dois. Você tem uma escolha infeliz: pausar o rewrite para perseguir o novo requisito (deixando tudo mais longo), ou ignorar o negócio (e entrega um sistema que não atende mais quando finalmente pronto).
O resultado é previsível: dois em cada três projetos assim não terminam, ou terminam com tempo e orçamento 2-3x maiores que planejado, com sêniors cassados, e equipes queimadas.
O Caso Que Ninguém Quer Contar
Há uma razão pela qual você vê mais artigos sobre “como fazer um rewrite direito” do que “aqui está a mensagem de erro que você vê quando um rewrite inteiro falha e precisa ser cancelado.” Os que falham não escrevem cases—eles silenciosamente desaparecem, e os líderes nunca falam sobre eles em conferências.
Mas há sinais. Reddit tem threads de engenheiros experientes dizendo coisas como: “Big Bang rewrites têm uma taxa de fracasso tão alta que é provável você ver a equipe antiga ser demitida depois de 2-3 anos de não-entrega que a equipe nova conseguir sucesso.” Isso é raiva documentada, não especulação.
Parte 2: O Custo Real de Não Fazer Nada
Agora, antes que você conclua “então simplesmente deixamos o sistema legado em paz,” entenda o outro lado do dilema.
Um sistema legado que apenas mantém o status quo é um dreno financeiro. Os custos são menos óbvios que um rewrite falhando, mas são muito mais devastadores ao longo do tempo.
Dinheiro Que Você Não Vê Deixando
Uma manufatura típica, por exemplo, paga até $260.000 por hora em custos de downtime não planejado. Se o seu sistema legado falha uma vez a cada trimestre por 2 horas (porque ninguém quer mexer nele, então acumula dívida técnica), você está perdendo $1 milhão por ano apenas em downtime—sem contar recuperação, perda de produtividade, ou reputação.
Serviços financeiros? Até $9.000 por minuto. Se você tem um sistema crítico de processamento de reclamações que falha sem aviso porque ninguém teve coragem de refatorar aquela seção acoplada do código, uma falha de 1 hora custa $540.000. Várias dessas ao ano, e você está falando de múltiplos milhões.
Mas os custos mais insidiosos são invisíveis:
- Custo de oportunidade: Sua melhor engenheira sênior passa 30% do tempo fazendo patches em código legado em vez de construir produtos que geram receita.
- Custo de inovação bloqueada: O sistema antigo não suporta análise em real-time, então você não pode construir um dashboard de ML que o concorrente acaba de lançar. Enquanto isso, clientes pulam.
- Custo de fuga de talento: Engenheiros bons não querem passar anos mantendo código legado. Eles saem. Você fica com os que não têm opção ou que não sabem o suficiente para sair.
- Custo de conformidade crescente: Regulação muda. O sistema antigo não suporta logging de auditoria fácil. Você contrata 2 pessoas para manter documentação manual, ou paga multas quando reguladores vêm.
Um estudo da Flexera mostra que custos de manutenção para sistemas legados crescem ano a ano, enquanto capacidade produtiva cai. Isso é uma curva de morte. Em algum momento, custa mais manter a coisa do que reconstruir.
A Bomba de Conhecimento
O sistema legado também tem outro inimigo invisível: pessoas. O engenheiro que escreveu 60% da lógica aposentou. O outro está aceitando uma oferta melhor e sai. Você fica com um sistema que ninguém entende completamente, que ninguém quer mexer, e uma mudança simples vira arqueologia.
Quando o conhecimento tácito sai, o risco explode. Mudanças pequenas introduzem bugs inesperados. Ninguém tem confiança para refatorar. Você entra em espiral KTLO (Keep The Lights On): apenas manutenção reativa, nunca estratégica.
Parte 3: Quando Reescrever Faz Sentido (Muito Raramente)
Agora, a honestidade: há casos em que um rewrite é a decisão certa. Apenas muito mais raros que as pessoas pensam.
Um rewrite completo faz sentido quando:
- O sistema é um “big ball of mud” genuíno, sem limites de módulo claros. Não é apenas desorganizado. É fundamentalmente impossível particionar. Toda mudança toca tudo.
- Os dados originais estão corrompidos ou mal estruturados de forma irreversível, e a arquitetura do banco não permite mudança gradual. Você não pode replicar dados enquanto executa ambos os sistemas.
- A equipe original desapareceu completamente, e não há documentação de negócio. O sistema é uma caixa preta. Ninguém consegue estimar o risco de refatoração.
- A tecnologia subjacente é tão obsoleta que suportar dois sistemas em paralelo é impossível. Por exemplo, um aplicativo em mainframe COBOL dos anos 1980 onde a plataforma subjacente não pode ser virtualizada.
- O negócio pode tolerar uma parada de 12-24 meses, e você tem capital e talent para queimar nela. Não é comum em empresas que competem em mercados vivos.
Fora desses cenários específicos—que afetam talvez 10-15% dos sistemas legados em produção—um rewrite é uma aposta, não uma estratégia.
Mesmo nesses casos, ainda há alternativas. Mas essa é a transição para a parte que importa: como você realmente moderniza sem o risco catastrófico do rewrite, e sem a resignação confortável de nunca mudar.
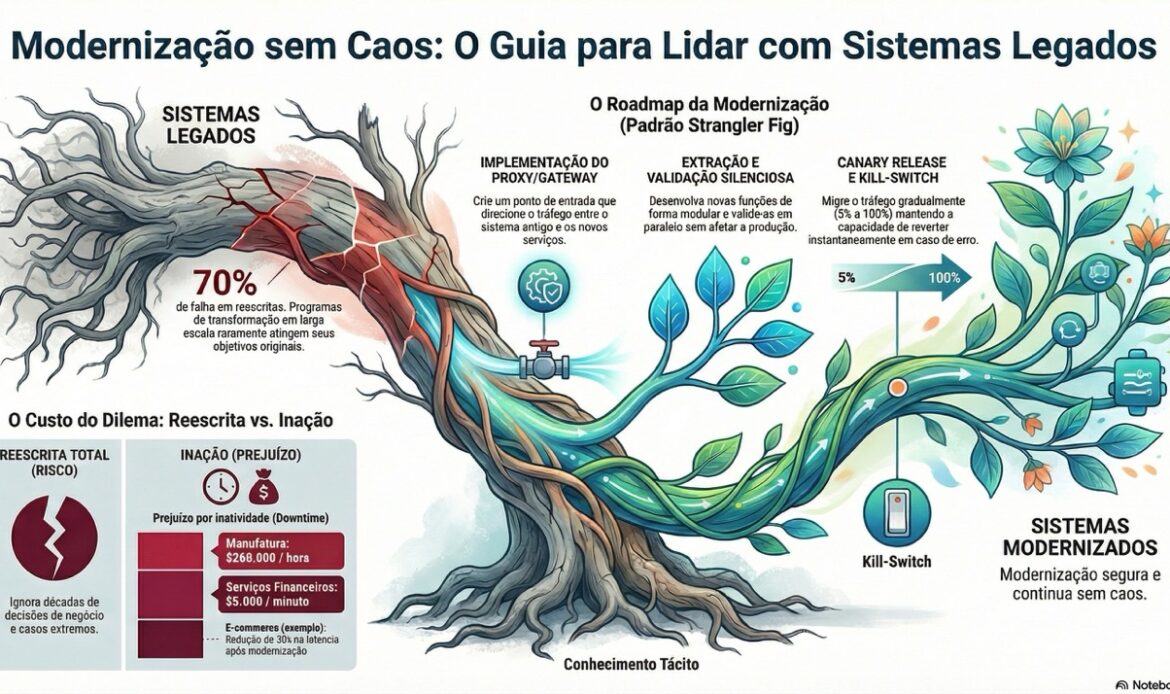
Parte 4: O Padrão Strangler Fig—A Maturidade Final
Existe um padrão que chegou perto de resolver esse dilema. Não é perfeito. Mas é tão mais próximo de realista que torna outras abordagens parecerem práticas de cargo culto.
Chama-se Strangler Fig Pattern.
O nome vem da biologia: uma figueira estranguladora cresce lentamente ao redor de uma árvore hospedeira. Ela não mata a árvore de uma vez. Envolve-a gradualmente, intercepta a luz e a água, até que eventualmente a árvore hospedeira morre de inanição—mas a figueira nunca precisa de um “big bang” para vencer. A transição é invisível.
Em sistemas de software, o padrão funciona assim:
O Conceito Básico
- Você coloca um proxy ou gateway na frente do seu sistema legado. Esse proxy é o novo ponto de entrada. Inicialmente, roteia 100% do tráfego direto para o sistema antigo.
- Você constrói um novo serviço para uma pequena, clara função do sistema antigo. Algo modular. Talvez “buscar preços de produtos.” Não é tudo. Apenas isso.
- Você faz o proxy rotear requisições para essa função para o novo serviço, mantendo tudo o mais no sistema antigo. O novo serviço processa, responde. O cliente nunca sabe.
- Você mede, valida, verifica discrepâncias. Se a nova implementação divergir da antiga em qualquer coisa, um alarme toca. Você não avança.
- Quando você tem confiança—4 semanas sem um único erro, por exemplo—você aumenta lentamente o tráfego. 5% para o novo, 95% para o legado. Observa. Aumenta para 10%. Observa.
- Quando 100% do tráfego está no novo serviço, você retira o código antigo dessa função do sistema legado. O proxy agora é responsável por rotear tráfego entre funções já migradas e funções ainda legadas.
- Você repete para a próxima função modular. E a próxima. E a próxima.
Ao fim de 3-5 anos, o “novo sistema” é na verdade um bando de microsserviços lean que substituíram gradualmente cada função do monolith antigo. O velho sistema morreu de inanição—mas nunca teve um interruptor desligado que quebrasse o negócio.
Por Que Isso Funciona (Quando Feito Bem)
O Strangler Fig Pattern é poderoso porque:
Reduz risco para tamanho-de-fatia. Você não está apostando 2 anos de engenharia em uma função que descobre ser impossível. Está apostando 6 semanas em uma coisa modular. Se falhar, você mata a tentativa, não o projeto inteiro.
Fornece feedback contínuo. Você não espera um ano para saber se cometeu um erro arquitetural. Sabe em semanas. Ajusta. Continua.
Permite que o negócio continue funcionando e mudando. O sistema legado ainda processa transações. Requisitos novos ainda podem ser adicionados (no legado, provisoriamente). Você não congela a organização por 2 anos em nome de um rewrite.
Distribui o custo ao longo do tempo. Em vez de um spike de CAPEX gigante no início, você tem despesa operacional constante. Melhor para orçamento, melhor para CFO, mais fácil de justificar.
Permite que os engenheiros aprendam conforme avançam. A primeira função que você extrai é lenta e frágil. A décima quinta é elegante e robusta. Você captura conhecimento de forma real.
Cria oportunidades de prova-de-conceito antes do compromisso total. Quer usar Kubernetes? Testa em uma função primeiro. Quer adotar uma nova linguagem? Constrói um novo serviço nela, vê se funciona, expande ou rejeita. Sem risco existencial.
Os Casos de Sucesso que Você Provavelmente Não Ouviu Falar
Empresas grandes já estão fazendo isso. Amazon extraiu microsserviços do seu monolith de varejo gradualmente—não tudo de uma vez. Netflix migrou do aplicativo DVD monolith para microservices incrementalmente, começando com os serviços stateless mais simples.
Mas há um caso que ilustra especificamente por que isso funciona quando alternativas falham. Uma empresa tinha um mecanismo de precificação legado escrito em VB6. O código tinha 380.000 linhas. Estava acoplado a stored procedures. Latência para calcular um preço único era 1.2 segundos. Toda mudança exigia regressão testing em semanas. Era o motor de um sistema de e-commerce. Reescrever era impossível sem parar as vendas.
Usando Strangler Fig:
- Criaram um novo serviço de precificação em .NET 8.
- Colocaram um proxy na frente.
- Começaram rotando cálculos de preço para o novo serviço, mantendo o legado como fallback.
- Construíram um loop de reconciliação automático que rodava a cada 5 minutos, comparando a saída do novo serviço com o antigo em dados de produção. Se houvesse divergência em qualquer campo, um alerta explodia no Slack.
- Migraram lentamente. 4 semanas sem qualquer discrepância? Aumenta para 10% do tráfego. Continua…
Resultado após 14 meses:
- Latência caiu de 1.2 segundos para 38 milissegundos. 30x mais rápido.
- Zero downtime durante a migração.
- Cada mudança de requisito foi validada em paralelo contra o antigo sistema.
- Risco estimado de inconsistência de dados que poderia custar à empresa $4.2 milhões foi completamente evitado porque o sistema de reconciliação detectava divergências em minutos, não semanas.
Isso é a diferença entre maturidade e fantasias de rewrite.
Parte 5: Como Evoluir Sem Parar o Negócio—O Roadmap Prático
Aplicar Strangler Fig não é “decidir fazer um rewrite lentamente.” É uma disciplina específica. Aqui está como.
Fase 1: Mapeamento e Priorização (2-4 semanas)
Primeira, você mapeia o sistema. Não modelos em Visio que ninguém mantém. Você instrumenta o sistema para entender o fluxo de tráfego em produção. Qual função é chamada quantas vezes? Qual consome mais latência? Qual falha mais?
Você então prioriza não por “o que parece fácil de reescrever,” mas por valor-de-negócio × risco × modularidade.
Uma função que é chamada um bilhão de vezes por dia mas é uma caixa preta acoplada? Risco alto. Prioriza mais tarde.
Uma função que é chamada um milhão de vezes por dia, tem limite claro, e está quebrando negócio? Prioriza agora.
Você normalmente começa com algo pequeno—um serviço que não é crítico, que é bem isolado, que não tem muita acoplamento cruzado. Você quer ganhar experiência antes de tocar no coração do sistema.
Fase 2: Construir a Infraestrutura de Roteamento (3-8 semanas)
Você não pode começar a migração sem um proxy que roteia inteligentemente. Esse proxy não é trivial.
Precisa ser capaz de:
- Rotear tráfego por regra (baseado em campos de requisição)
- Suportar canary releases (5% para novo, 95% para legado)
- Ter feature flags (se uma flag está desligada, roteia de volta para legado mesmo que o novo esteja ligado)
- Registrar tudo para observabilidade
- Ter um kill-switch que pode reverter 100% do tráfego para legado em segundos
Sim, segundos. Não minutos. Segundos. Se o novo serviço começar a derramar fogo, você precisa voltar para o legado sem pedir permissão a ninguém.
Isso é infraestrutura cara de construir. Mas é o preço de não apagar a empresa.
Fase 3: Extrair a Primeira Função (6-12 semanas)
Você constrói uma nova implementação de uma função pequena e modular. Não é uma reescrita cuidadosa. É uma “qual é a forma mais simples de implementar isso corretamente, com todos os casos extremos?”
Enquanto constrói, você está em paralelo:
Instrumentando a função legada para capturar todas as entradas e saídas que qualquer função completa gera.
Construindo um loop de reconciliação. Esse loop roda a cada 5 minutos em produção. Pega os eventos de entrada da última hora, roda contra o novo serviço, compara contra a saída do legado. Se houver divergência em um único campo, registra exatamente qual é a divergência e grita alarme.
Escrevendo testes da vida real contra dados de produção. Dados de teste que você inventou em um spreadsheet? Inúteis. Você pega milhões de transações reais do seu sistema legado, rodas contra o novo serviço, vê o que quebra.
Você não deploy esse novo serviço em produção ainda. Apenas deixa rodando off-stage, processando dados históricos.
Fase 4: Validação Silenciosa em Produção (2-4 semanas)
Você finalmente coloca o novo serviço ao vivo. Mas 0% do tráfego vai para ele.
Ao invés, você coloca um tee na frente. Toda requisição que chega ao proxy, você copia (sem afetar a requisição original) e envia para o novo serviço. O novo serviço processa, retorna resposta, mas essa resposta é descartada. Apenas para exercitar o código em cenário de produção.
Você deixa isso rodar por uma semana. Observa logs, observa erros, observa latência.
Se o novo serviço despencar quando confrontado com tráfego real de produção? Você aprende. Reifica. Roda novamente a semana que vem.
Se passar uma semana sem problemas criticos? Avança.
Fase 5: Canary Release (1-2 semanas)
Você configura o proxy para rotear 5% do tráfego real para o novo serviço. 95% continua no legado.
Agora há pressão real. Clientes reais estão sendo servidos. Há latência real. Há dados reais que você nunca viu antes.
Seu loop de reconciliação roda a cada 5 minutos. Se há divergência? Tira um screenshot, alerta, e você investigar.
Você deixa rodar por 2-3 dias. Se tudo está limpo, aumenta para 10%. Deixa rodar 2-3 dias. 25%. 50%. 100%.
Se em algum ponto há um problema, você desceu para 0% em segundos e voltou para debug.
Fase 6: Aposentadoria do Código Legado (1 semana)
Quando 100% do tráfego está no novo serviço por 4 semanas sem uma discrepância, você opcionalmente remove o código dessa função do sistema legado.
Digo opcionalmente porque alguns times deixam o código antigo lá, dormindo, para sempre. Oferece uma rede de segurança se alguém acidentalmente chamar a rota antiga. Seu custo é negligenciável se não está rodando.
Outros times remove porque é satisfação. Você erased a função do monolith. Você a substituiu.
Fase 7: Repetir
Você volta para Fase 1 com a próxima função priorizada. Você agora não tem 6-12 semanas de incerteza. Tem um playbook que funciona. Você roda mais rápido.
A segunda função leva 8 semanas. A terceira, 6. A décima, você tem fábrica.
Exemplo Concreto de Roadmap: E-commerce
Digamos você tem uma plataforma de e-commerce com um monolith Python de 500k LOC. Quer modernizar.
Meses 1-2: Mapear sistema. Identificar que “buscar detalhes de produto” é chamado 500 milhões de vezes por dia, é isolada, e impacta 20% da latência fim-a-fim. Prioriza aqui primeiro.
Meses 2-3: Construir proxy. Instalar observabilidade.
Meses 3-5: Construir novo serviço de detalhes de produto em Go. Rodar testes contra 6 meses de logs.
Meses 5-6: Tee traffic silenciosamente. Debugar.
Meses 6-7: Canary, aumentar gradualmente.
Mês 7: Aposentar código antigo.
Então:
Mês 7-9: Próxima função—”processar pedidos”—é maior, mais acoplada. Leva 8 semanas.
Mês 9-11: “Autenticação de usuário”—estateless, rápida, 6 semanas.
Pula para frente 18 meses. Você tem 10 serviços modernos. O monolith está 40% mais magro. Você viu real data corruption risks em 3 funções e as fixou antes de ir para produção. A equipe que trabalha em novos serviços é 2x mais rápida que o time no monolith porque arquitetura é clara. Você começou a atrair engenheiros bons de volta.
18 meses. Sem downtime. Sem rewrite miserável que dura 3 anos e falha.
Parte 6: Armadilhas Reais—O Que Mata Migrations Mesmo Com Strangler Fig
O Strangler Fig Pattern é poderoso. Mas é frágil. As pessoas o matam de formas previsíveis.
Anti-Pattern 1: Começar Pela UI
O erro mais comum é decidir “vamos reescrever a interface, ixo é visualizador e vamos ganhar quick win.”
Resultado? A nova UI está conectada aos mesmos serviços legados antigos. Herda todos os acoplamentos. Ficou um mess distribuído—a interface está em Typescript novo e elegante, mas fala com 40 serviços legados tightly coupled, e cada serviço sabe sobre cada outro. Você não simplificou nada. Apenas espalhou.
Comece de dentro para fora. Extraia serviços do núcleo do negócio primeiro. Deixe a interface falar com eles. A interface é a coisa mais fácil de reescrever quando o backend está limpo.
Anti-Pattern 2: “Just One More Field”
Você começou a extrair a função “buscar cliente.” Parecia bem isolada.
Mas alguém diz “e se o cliente também retornasse últimas 3 vendas? Seria útil.”
Parece simples. Você adiciona. Agora “últimas 3 vendas” precisa de acesso aos dados de vendas, o que envolve relacionais complexos, o que envolve permissões, o que envolve auditoria.
De repente seu “serviço de cliente isolado” depende de 5 other serviços antigos.
Resultado? Seu novo serviço nunca estabiliza. Nunca fica isolado o suficiente para matar o código antigo. A boundary fica fuzzy. Você fica preso.
Disciplina: contrato entre novos e legado não muda sem revisão arquitetural. Alguém pede “just one more field”? Você diz não. Eles fazem request formal, você revisa a dependência, você cuida de retorno de dados. Mas não é casual.
Anti-Pattern 3: Não Ter Reconciliação Robusta
Você levanta o novo serviço sem um loop de reconciliação. “Nós vamos testar bem, vai dar certo.”
Semanas depois, você descobre que em 0.3% das transações, o novo serviço retorna um resultado ligeiramente diferente do legado. Não pelas mesmas razões (bug novo), mas porque você não replicou exatamente um edge case da lógica antiga. Clientes começam reportando problemas.
A reconciliação automática teria detectado isso em 5 minutos.
Seu loop precisa ser robusto: eventos determinísticos (você hasha a requisição para dedup e match), comparação campo-por-campo, alertas rápidos, e um limite simples: se há divergência, você pausa a migração daquela função e investiga.
Vai levar tempo? Sim. Diárias. Meses. Mas isso é tempo gasto descobrindo o desconhecido, não tempo gasto explicando para clientes por que seu novo sistema quebrou.
Anti-Pattern 4: Killing the Kill-Switch
Você tem confiança. Você já rodiou o novo serviço 4 semanas sem erro. “Vamos desligar o fallback pro legado. O novo é a verdade agora.”
Um dia, alguém faz uma requisição edge case que ninguém testou. Boom. Erro 500. Agora tem downtime. Agora está apagando fogo.
Você nunca desativa o kill-switch. Sempre mantenha a capacidade de voltar para 100% legado em segundos. Mesmo que acredite 99% que não vai precisar.
Parte 7: Quando o Strangler Não é Suficiente
Há cenários em que o Strangler Fig simplesmente não funciona. Não porque o padrão é fraco, mas porque o sistema é tão acoplado que particionar é impossível.
O True “Big Ball of Mud”
Se sua base de código é um big ball of mud genuíno—toda função chama toda outra função, há ciclos de dependência, há estado global compartilhado por tudo—você não consegue extrair uma função sem extrair 80% do sistema.
Nesse caso, você tem algumas opções:
Option 1: Rearchitetar em paralelo. Constrói um novo sistema em paralelo por 1-2 anos, mas ao invés de migrar dados, você constrói um wrapper/adapter que fica na frente do novo sistema. Internamente, o novo sistema replica toda a lógica do antigo. Então você muda o proxy para apontar para o novo. Funciona? Saca a velha. Não funciona? Volta.
Isso é ainda menos risco que um rewrite porque você tem fallback. Mas é caro porque você está escrevendo tudo duas vezes.
Option 2: Morte lenta. Você aceita que o sistema é legado. Você reduz investimento nele. Você para de construir features novas. Você apenas a mantém viva enquanto constroi uma substituição completa em paralelo (diferente, nova stack, nova tudo). Quando o novo estiver pronto, você faz um cutover (sim, risco, mas ao menos você tentou tudo mais primeiro).
Essa é uma abordagem legítima, mas requer que você tenha capital e paciência.
Dados Corrompidos Irreversivelmente
Se o banco de dados tem schema incoerente, dados sujos que foram “limpos” em triggers noturnos, relacionais que ninguém entende, você pode não conseguir replicar dados limpos para um novo sistema.
Nesse caso, você precisa de:
- Projeto de limpeza de dados primeira (3-6 meses). Você mapeia cada problema, constrói um plan de limpeza, valida que dados saem correctamente.
- Depois você pode extrair funções gradualmente.
Mas isso é preparação, não “não faça Strangler Fig.”
Parte 8: Medindo Sucesso e ROI
Como você prova que essa abordagem incremental está funcionando?
Métricas Que Importam
Custo de manutenção reduzido: Quantos sêniors estão passando 100% do tempo fixando bugs legados vs construindo features novas? Com Strangler, essa razão muda. Não porque bugs desaparecem, mas porque o novo código tem menos bugs porque foi escrito com padrões melhores.
Velocidade de release: Com quantos dias de lead time você solta features? Monolith antigo? 30 dias de média. Um novo microsserviço? 2-3 dias. Conforme mais funções migram, sua velocidade geral accelerates.
Latência fim-a-fim: Seu sistema está mais rápido? Usuários notam? Isso traduz em conversão, retention. Uma startup de e-commerce reduzindo latência em 30% geralmente vê 5-10% bump em conversão (não ciência, mas padrão observado).
Mean Time to Recovery (MTTR): Um bug em um novo serviço leva 2 horas para você descobrir e fixar? Um bug no legado leva 2 dias porque o código é opaco? MTTR melhorando é sinal que você está progredindo.
Developer Retention: Seus engenheiros bons estão saindo ou ficando? Trabalhar em sistemas legados queima pessoas. Trabalhar em microserviços nova e elegantes as energiza. Isso é financeiro (custo de hiring e onboarding) e cultural.
Medindo ROI Financeiro Mesmo Em Andamento
Você não precisa esperar 5 anos de modernização completa para justificar o investimento. Você justifica a cada slice:
A primeira função que você extrai custa, digamos, $200k (salários da engenharia, infraestrutura, etc.) por 6 meses.
Que benefício você obtém?
- Aquela função que causava 5% do downtime agora causa 0.1%. Se downtime custava $500k por ano, você economiza ~$250k. Payback em 1 ano.
- Latência dessa função caiu 20x. Features novas que dependem dessa função agora são viáveis. Estima receita potencial: $50k por ano.
- Um engenheiro sênior que passava 50% do tempo mantendo essa função agora passa 100% em coisas novas. Impacto na produtividade: 30% boost em throughput engenharia.
Financeiramente? Payback em 1-1.5 anos, e benefícios contínuos depois disso.
A segunda função que você extrai custa menos (você tem playbook agora): $150k. Benefícios? Maiores, porque você está mejorando uma coisa que você já otimizou.
Ao mês 24, você tem 3-4 funções migradas, custos caíram 20% (menos manutenção legada), velocidade dobrou, downtime caiu 40%. CFO pode ler isso: ROI positivo, com expectativa de 40-60% economia em 3-5 anos.
Não é rewrite que promete 10x e entrega nada. É modernização que entrega 20-30% ganho hoje, e mais amanhã.
Parte 9: A Verdade Sobre Maturidade
A razão pela qual senior engenheiros que ouviram essa história antes entendem imediatamente é porque ela é sobre risco, não sobre tecnologia. Rewrite é risco extremo. Negligência indefinida é risco também (evoluindo, crescendo, até que falha catastrofica). Strangler é risco gerenciado em fatias.
Maturidade final em engenharia não é saber escrever a maioria linguagem mais nova, ou conhecer o padrão de design mais moderno. É saber quando não fazer algo, por que não fazer, e como fazer o caminho do meio que ninguém quer tomar porque é mais lento que fantasy e mais caro que negligência.
Rewrite é fantasy. Negligência indefinida é o que pessoas fazem quando têm medo. Strangler Fig é o que você faz quando entende que o negócio que você trabalha precisa se mover, mas não pode se quebrar.
Conclusão: O Que Você Leva Para a Próxima Segunda
Se você é um senior que enfrenta um sistema legado, aqui está o playbook:
- Não reescreva. Não acredite na promessa. 70% das grandes transformações falham. Você não é exceção.
- Não ignore. Custos crescem, risk grows, equipe sai. Inação é sua maior ameaça.
- Mapeie o sistema. Entenda onde a dor é pior. Não em teoria—em produção, com dados reais.
- Comece pelo núcleo, não pela interface. A função mais isolada, mais dolorosa, mais impactante em latência ou downtime.
- Constrói infraestrutura primeiro. Proxy, reconciliação, kill-switch. Sua rede de segurança. Ela custa agora, economiza depois.
- Extrais, validas em silêncio, canary, expande, aposentas. Nenhuma pressa. Meses por função. Não semanas.
- Medis tudo. Você quer dados que provam isso está funcionando. CFO quer dinheiro. Clientes querem velocidade. Você mostra tudo isso em paralelo.
- Mantem o kill-switch sempre. Mesmo com 99% confiança, você reverta em segundos.
- Nunca chama isso um “rewrite”. Chama modernização incremental, migração gradual, evolução arquitetural. Porque é. O novo sistema cresce lentamente, o velho morre lentamente, e o negócio nunca pausa.
Isso é onde a maturidade final mora. Não em código novo. Em decisões que você faz quando ninguém está te vendo, e elas determinam se a empresa está aqui em 5 anos ou se explodiu em uma aposta de rewrite.
Para o sênior que chegou até aqui: você já sabe disso. Talvez você não tinha as palavras. Talvez você tinha as palavras mas ninguém ouvia. Leva isso para sua equipe. Leva para seus stakeholders. Leva para seu CFO. É como você vence.