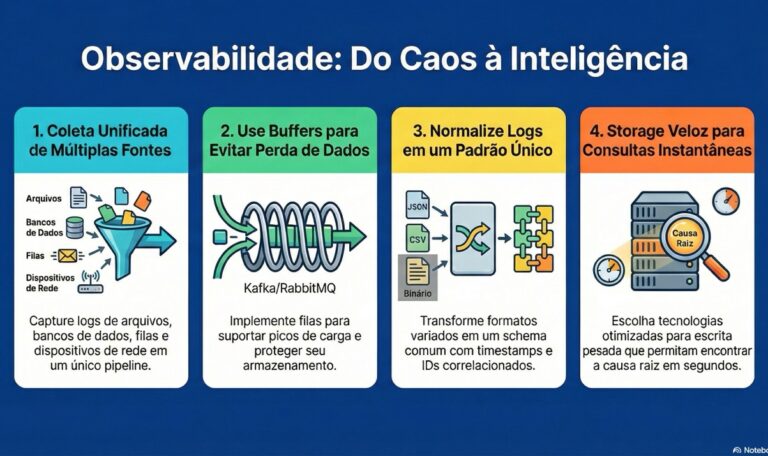
🧩 A fronteira real: quando os erros chegam por todos os lados Aqui está a dor que separa time que “tem log” de time que “enxerga o sistema”: seus erros estão espalhados em formatos e canais que não conversam. O aplicativo mobile gera crash em arquivo de texto no dispositivo. O backend Java loga em JSON para stdout. A fila de mensagens (Kafka/RabbitMQ) registra dead letters em binário. O banco de dados tem sua própria tabela de auditoria. E ainda tem o syslog do sistema operacional, os logs de acesso do nginx, e as exceções que o time de suporte recebe via Slack/Telegram quando um usuário rage-quita. Se você precisa abrir cinco ferramentas diferentes para traçar um único incidente, você não tem observabilidade. Tem um caos organizado. A arquitetura que resolve isso Para receber erros de múltiplas fontes e transformar em inteligência acionável, você precisa de quatro camadas funcionando em conjunto: 1. Coleta multi-protocolo (os “agentes” ou log shippers) Cada fonte exige uma estratégia diferente: 2. Fila de buffer (o salva-vidas em escala) A eterna verdade de quem rodou sistema grande: nunca mande log direto para storage. A taxa de ingestão varia demais. Em pico de erro, seu banco de logs vai cair se receber diretamente de milhares de instâncias. A solução é uma camada de buffer: Kafka, RabbitMQ, ou até Redis em casos menores. Os agentes enviam para a fila. O processador consome da fila. Se o storage ficar lento, a fila cresce — mas você não perde dados. Isso também desacopola “geração de log” de “processamento de log”, permitindo que você pause o parser sem perder eventos. 3. Normalização e enriquecimento (onde a mágica acontece) Aqui é que muita implementação amadora morre. Você recebe: Precisa de um parser que normalize tudo para um schema comum: timestamp, severity, service, trace_id, mensagem, metadata. E enriqueça: adicione hostname, região da cloud, versão do deploy, ID do pod Kubernetes. Sem isso, você não consegue correlacionar “erro no banco” com “retry excedido no serviço X”. 4. Storage e consulta (onde você vai quando o pager toca) O storage precisa ser otimizado para write-heavy (você escreve muito mais do que lê). Elasticsearch, Loki, ClickHouse, ou até S3 com Athena são opções viáveis. O que importa é: você consegue, em segundos, buscar por trace_id que atravessa 12 serviços diferentes? Se a resposta for “demora 2 minutos”, você vai perder o incidente. O desafio do profissional sênior: correlação distribuída Ter todos os logs no mesmo lugar é só o começo. O problema real é: como você sabe que o erro no microserviço A causou o timeout no B, que gerou a mensagem de erro no banco C? Você precisa de distributed tracing (trace_id propagado via headers HTTP, mensagens de fila, e até calls de banco) + logging estruturado que inclua esse trace_id em cada evento. Só assim você consegue, em uma única query, reconstruir a jornada de uma requisição que falhou em qualquer ponto da arquitetura. Alertas que fazem sentido (e não spam) Com todos esses dados centralizados, você pode criar alertas baseados em padrões, não só thresholds: Isso é só possível quando você conseguiu unificar logs de aplicação, infraestrutura e mensagens em um único sistema de consulta. Essa arquitetura não é “overengineering” — é o mínimo para qualquer sistema que tenha mais de três serviços e uptime que importa para o negócio. A boa notícia: ferramentas como OpenTelemetry, Fluentd, Kafka e Elasticsearch (ou soluções gerenciadas como Datadog, Splunk, Signoz) já resolvem 80% do problema. Os 20% restantes são configuração correta de parsers, garantia de entrega (exactly-once vs at-least-once), e decisões de retenção (o quanto você guarda e por quanto tempo, considerando custo). Se você está hoje abrindo SSH em 15 máquinas diferentes para caçar um erro, ou puxando dump de tabela de log manualmente, você está gastando tempo de engenheiro sênior em tarefa que deveria ser automatizada. E pior: está assumindo risco de perder o erro crítico que está escondido na fonte que você esqueceu de olhar.