
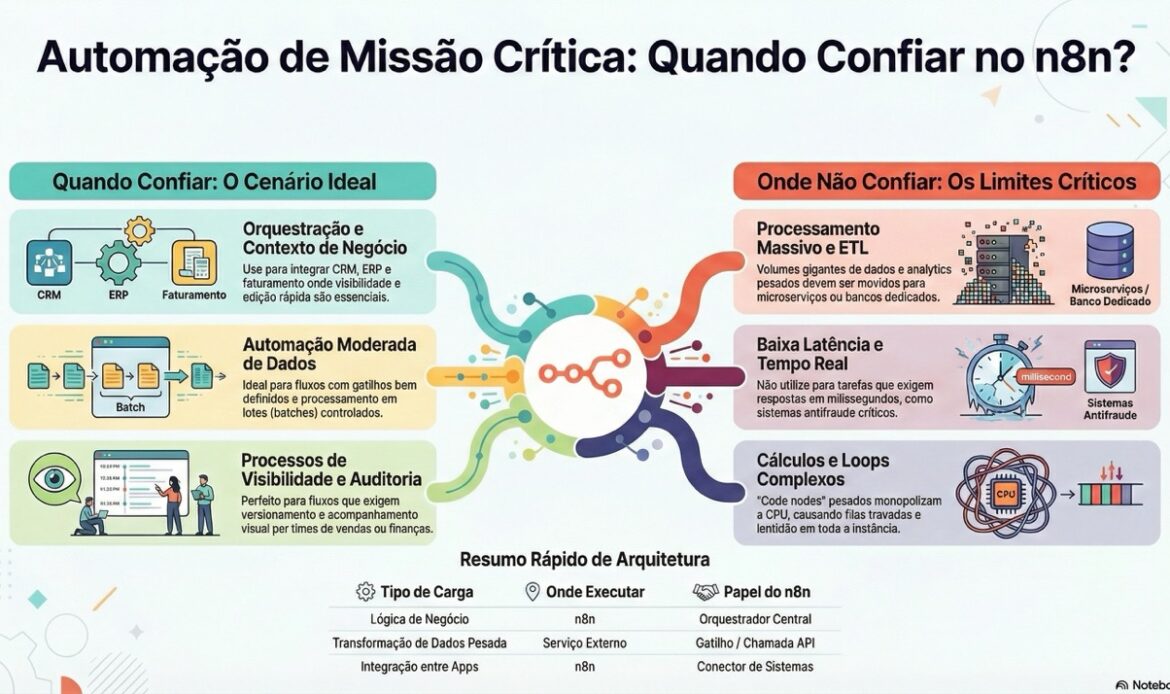
Quando você usa o n8n como camada central de automação, ele vira parte da sua infraestrutura de missão crítica — só que muita gente ainda trata como “ferramenta de no-code divertida”.
O resultado: filas crescendo, execuções travadas, time reclamando de lentidão e o negócio inteiro dependendo de um único container mal dimensionado.
Se você roda:
- Processamento pesado de dados
- Integrações em larga escala (CRM, ERP, billing)
- Rotinas sensíveis a tempo (pagamentos, SLA de lead, antifraude)
então você precisa tratar o n8n como trataria qualquer outro componente crítico: com limites claros, monitoramento e arquitetura pensada para falhar com segurança.
🔁 Concorrência vs paralelismo no n8n (sem ilusão)
No discurso de marketing, “roda tudo em paralelo”. Na prática, existem limites bem concretos.
🧱 Níveis de concorrência no n8n
- Concorrência da instância
- Concorrência por worker (queue mode)
- Concorrência por workflow
📌 Tradução prática: o “paralelismo” que você imagina talvez não exista. Você pode ter 200 eventos chegando, mas só 20 sendo realmente processados — o resto está em fila esperando slot.
🧨 Onde surgem os gargalos de execução
Na teoria o gargalo é “o recurso mais lento”. Na prática com n8n, ele costuma aparecer em alguns pontos previsíveis.
🔍 Gargalos típicos dentro do n8n
- Salvar tudo no banco
- Payloads gigantes passando de nó em nó
- Code nodes fazendo trabalho de microserviço
- Triggers e crons mal desenhados
🌐 Gargalos fora do n8n (mas sentidos nele)
- APIs externas com rate limit ou latência alta
- Banco de dados externo lento
- Rede mal posicionada (n8n longe dos serviços principais)
O efeito é o mesmo: execuções ficam abertas por muito tempo, ocupam slots de concorrência e seguram tudo que vem depois.
🧱 Quando o n8n vira o bottleneck (sinal amarelo)
Há um ponto em que não é mais “falta de memória no servidor”, é arquitetura errada em cima do n8n.
🚨 Sinais de que o n8n virou gargalo
- Fila sempre cheia, com número de execuções ativas travado no limite de concorrência (ex: sempre 10 ativas e o resto aguardando).
- P99 de tempo de execução crescendo mesmo sem mudança de carga ou lógica.
- Workers batendo em limites de conexão do banco por excesso de processos concorrentes.
- Necessidade constante de “aumentar máquina” sem ganho proporcional de throughput.
Na nuvem do n8n, isso aparece como atingir o limite de execuções concorrentes do plano (ex: 5, 20, 50, 200 conforme o plano).
Em self-hosted, aparece como “por que só estou processando 10 execuções se tenho 3 workers com --concurrency=20?” — e a resposta muitas vezes está em variáveis de ambiente como N8N_CONCURRENCY e N8N_CONCURRENCY_PRODUCTION_LIMIT mal configuradas.
🧠 O erro de raciocínio mais comum
Tratar o n8n como se fosse:
- Message broker
- Orquestrador distribuído de longa duração
- Data pipeline de alto volume
Ele não foi feito para ser tudo isso ao mesmo tempo.
Você consegue empurrar até certo ponto com queue mode + múltiplos workers + tuning, mas existe um teto prático.
👉 Nem toda automação deve passar pelo n8n
Esse é o ponto que mais dói admitir quando você é fã da ferramenta: n8n não é o lugar certo para todo tipo de carga.
✅ O que faz sentido centralizar no n8n
- Orquestração de integrações entre sistemas
- Workflows com contexto de negócio, automação de time de vendas, financeiro, operações
- Processos que precisam de visibilidade, versão, auditoria e edição rápida via UI
- Automação moderada de dados (batches controlados, triggers bem definidos)
Nesses cenários, use intensamente:
- Concurrency control por workflow e por instância.
- Queue mode com workers separados por tipo de carga (ex: “API leve” e “processamento pesado”) e concorrências diferentes.
- Otimizações como redução de salvamento de execuções e tuning de banco.
❌ O que você deveria tirar do n8n
- Processamento massivo de dados (ETL de alto volume, transformação pesada, analytics) — melhor empurrar para serviços especializados ou jobs dedicados (ex: microserviço + fila).
- Processos de baixa latência e alta criticidade (ex: antifraude em tempo real, roteamento que precisa responder em milissegundos).
- Cálculos pesados, machine learning, loops gigantes em Code nodes — isso explode CPU e piora todas as outras automações.
📌 Regra prática para fluxos críticos:
Se a falha ou lentidão do fluxo derruba receita em tempo real ou compromete compliance, o n8n deve orquestrar, não executar o coração do processo.
Use o n8n como:
- Entrada → validação básica → chamada para um serviço dedicado → retorno/registro.
- E não como: “todo o processamento de negócio mora aqui”.
📈 Plano prático para quem leva fluxos críticos a sério
Se você já tem fluxo crítico rodando em n8n hoje, um plano direto:
- Mapeie onde o n8n está no caminho crítico de receita ou SLA
- Liste fluxos sem os quais o negócio para.
- Marque quais dependem 100% do n8n funcionar rápido.
- Ligue o radar de performance
- Aplique tunings simples antes de escalar infra
- Reveja arquitetura onde o n8n claramente é o gargalo
- Defina o que nunca mais vai passar “inteiro” pelo n8n
🚀 Call to action
Se você quiser, no próximo passo podemos pegar um fluxo crítico seu específico (por exemplo, “pipeline de leads”, “faturamento”, “notificações em massa”) e:
- Desenhar onde o n8n deve ficar.
- Marcar onde estão os gargalos mais prováveis.
- Propor uma arquitetura híbrida: o que fica no n8n, o que sai para serviços externos.
Você ganha clareza, reduz risco de outage e para de depender da sorte quando a carga real bater.